


Snowflake: Pre-Requisite to Get Started
In this blog, I'm discussing the pre-requisites knowledge required to get started with Snowflake.


The definition of Snowflake is that it is a cloud-based data warehousing platform that provides a fully managed, scalable, and secure solution for storing, managing, and analyzing large amounts of data. Whenever and wherever you'll hear of Snowflake, you'll always find the term 'cloud-based data warehouse'. So, let's understand it.
What's a Data Warehouse?
A data warehouse is a centralized repository that stores integrated and organized data from one or more sources and is designed to support business intelligence (BI) and analytical reporting. The purpose of a data warehouse is to provide a single, reliable and consistent source of truth for business users to make informed decisions.
A data warehouse is designed around business topics or subjects, such as sales, customers, products, or finances. This allows users to analyze data from a business perspective, rather than a technical perspective. It integrates data from multiple sources, such as transactional systems, legacy systems, and external sources. This provides a unified view of the organization's data and enables cross-functional analysis. It also stores historical data over time and enables users to analyze data trends and patterns. This supports business users in making informed decisions based on past performance. It is a read-only database that is optimized for querying and reporting. Once data is loaded into the data warehouse, it is not updated or deleted without user intervention, which ensures the accuracy and consistency of data.
Data warehouses typically use a dimensional data model, which organizes data into fact tables and dimension tables. Fact tables contain numerical measures or metrics, while dimension tables contain descriptive attributes or hierarchies.
How is a Data warehouse different from a Database?
A database and a data warehouse are two distinct types of data management systems, with different purposes, structures, and features.
A database is a software system that is designed to manage and store structured data, such as customer information, inventory, and financial transactions. A database uses a schema or a data model to define the structure and organization of data and provides features such as data validation, transaction processing, indexing, and query optimization. A database is typically used to support transactional processing, such as adding, updating, or deleting data in real time.
A data warehouse, on the other hand, is a centralized repository that stores integrated and organized data from one or more sources and is designed to support analytical reporting. A data warehouse uses a dimensional data model and provides features such as data transformation, data aggregation, data cleaning, and data mining. A data warehouse is typically used to support decision-making processes, such as analyzing trends, patterns, and performance over time.
Here are some key differences between a database and a data warehouse:
Purpose: A database is designed for transaction processing, while a data warehouse is designed for analytical processing.
Data Structure: A database is designed to store structured data, while a data warehouse can store both structured and unstructured data.
Data Volume: A database can handle large volumes of data, but is optimized for processing individual transactions or small batches of data, while a data warehouse is designed to handle large volumes of data and support complex analytical queries.
Data Model: A database uses a relational data model, which organizes data into tables with defined relationships between them, while a data warehouse uses a dimensional data model, which organizes data into fact tables and dimension tables.
On-premise vs Cloud Warehouse
On-premise data warehouses are physical servers and storage infrastructure that are located within an organization's own data centre or facility, while cloud data warehouses are hosted on a third-party cloud service provider's infrastructure and accessed through the internet.
Here are some key differences between on-premise and cloud data warehouses:
Infrastructure: On-premise data warehouses require the organization to purchase and maintain hardware, software, and networking infrastructure, while cloud data warehouses are managed by the cloud service provider and do not require any infrastructure maintenance.
Scalability: On-premise data warehouses have limited scalability and may require significant investment to upgrade or expand, while cloud data warehouses offer virtually unlimited scalability and can easily scale up or down as needed.
Cost: On-premise data warehouses typically have high upfront costs for hardware and software, as well as ongoing maintenance costs, while cloud data warehouses have a pay-as-you-go pricing model, which means organizations only pay for what they use.
Security: On-premise data warehouses offer complete control over data security and compliance, while cloud data warehouses offer varying levels of security and compliance, depending on the cloud service provider and the specific configuration.
Maintenance and Support: On-premise data warehouses require in-house IT staff to maintain and support the infrastructure, while cloud data warehouses are managed and supported by the cloud service provider.
Why do we need a cloud-based Data Warehouse?
To understand the actual need, we first need to understand the basic flow of data. So, the data emanates from a data source like operational, CRM, ERP tools, or SQL and reaches BI tools like Tableau, Microsoft's PowerBI, or Google's Looker. The flow of data from a source to a Business Intelligence (BI) tool involves several stages.
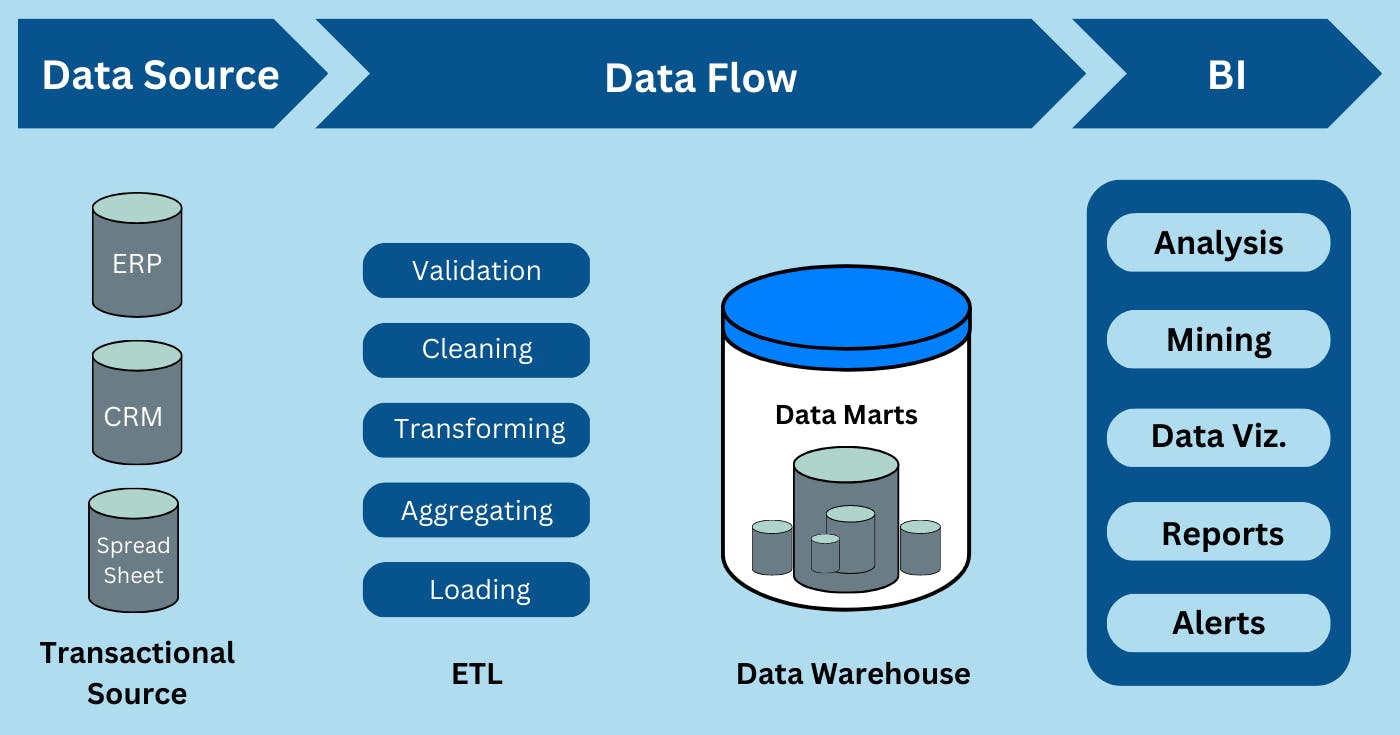
Data Extraction: This is the very first stage of the data lifecycle. In this stage, data is extracted from various sources such as databases, flat files, APIs, or cloud services. Data can be extracted using different methods such as batch processing, streaming, or real-time data ingestion.
Data Transformation: Once the data is extracted, it needs to be transformed into a format that can be used for analysis. This stage involves cleaning, filtering, and restructuring the data to remove any inconsistencies, errors, or redundancies. The transformed data is typically stored in a data warehouse or data lake.
Data Modeling: Now, the transformed data is modelled into a structure that makes it easier to analyze. The data is organized into tables, dimensions, and measures that reflect the business logic and the relationships between different data elements.
Data Storage: The modelled data is stored in a database or a data warehouse, which can be optimized for performance and scalability. The data is typically stored in a columnar format that allows for faster querying and analysis.
Data Querying: In this stage, users can query the data stored in the data warehouse using SQL or other query languages. Users can create ad-hoc queries or pre-defined reports to get insights into the data.
Data Visualization: Once the data is queried, it can be visualized using a BI tool. The BI tool provides different visualization options such as charts, graphs, and tables that make it easier to understand the data. Users can also create interactive dashboards that allow them to explore the data in real time.
Data Analysis: Finally, users can analyze the data to gain insights and make data-driven decisions. They can use different analysis techniques such as trend analysis, forecasting, or predictive analytics to identify patterns and trends in the data.
So, to store any volume of data without any upfront cost, infrastructure upgrade, maintenance and support, we need a cloud-based data warehouse. And, snowflake serves the need for a cloud-based data warehouse.
Cloud Service Models
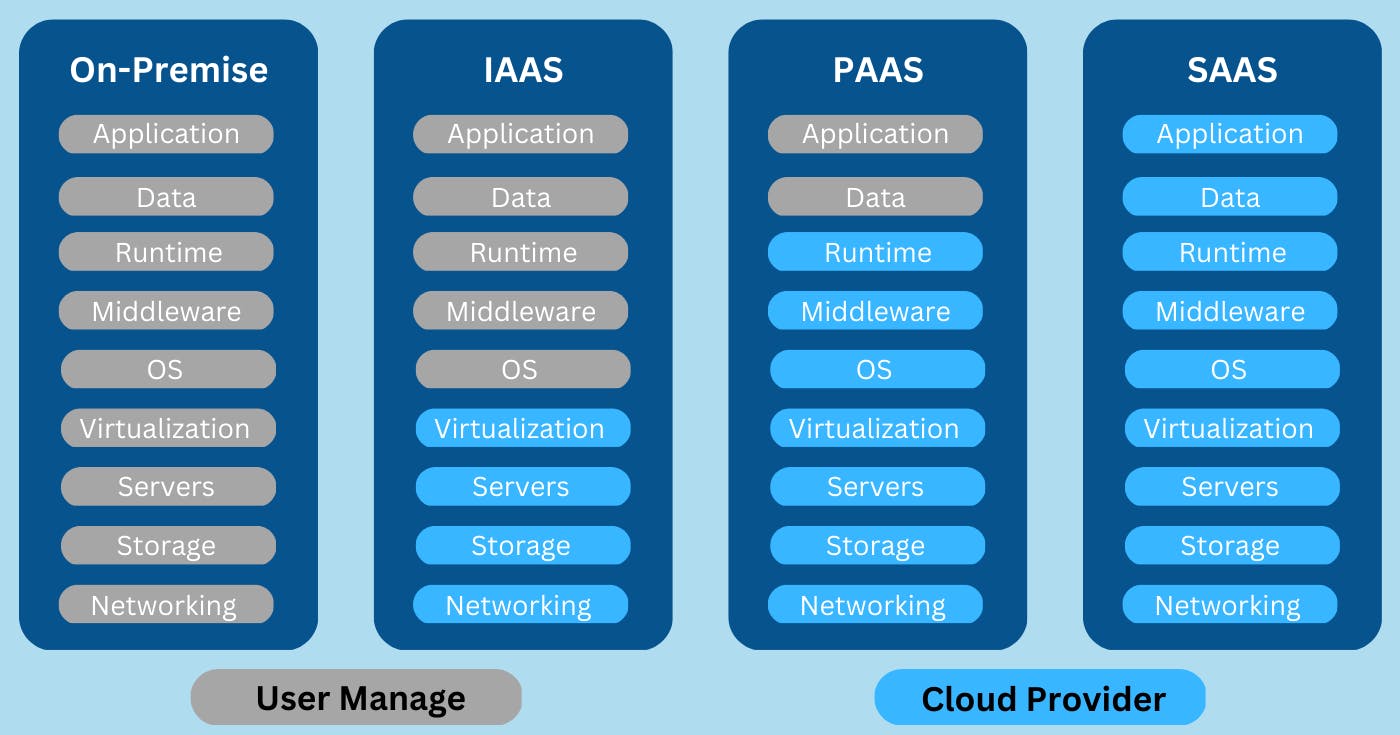
Snowflake provides its services on the Infrastructure as a Service (IaaS) model. Specifically, it runs on top of AWS, Azure, and GCP and leverages the computing power and storage resources of these cloud providers. By using IaaS, Snowflake provides with a pay-as-you-go pricing model and the ability to scale their computing and storage resources up or down as needed.
Infrastructure as a Service (IaaS): In this model, the cloud service provider offers virtualized computing resources, such as servers, storage, and networking, on a pay-per-use basis. Customers can provision, manage, and monitor these resources themselves, and are responsible for installing and configuring their own operating systems, middleware, and applications.
Platform as a Service (PaaS): In this model, the cloud service provider offers a platform for developing, deploying, and managing applications, without the need for customers to manage the underlying infrastructure. The provider typically offers pre-configured operating systems, middleware, and application development tools, as well as automated scaling and management services.
Software as a Service (SaaS): In this model, the cloud service provider offers fully managed applications, which are accessible to customers over the internet. The provider is responsible for maintaining the underlying infrastructure, as well as upgrading and patching the software. Customers typically pay a subscription fee based on usage.
Function as a Service (FaaS): In this model, the cloud service provider offers a serverless environment for running code in response to events or triggers, without the need for customers to manage the underlying infrastructure. Customers upload their code to the cloud provider, which automatically scales and executes the code in response to events or triggers.
Types of Database Systems
Snowflake is primarily an OLAP platform designed for data warehousing and analytics workloads. It also supports some OLTP workloads, allowing users to perform simple transactions and data manipulation tasks on their data.
OLTP (Online Transaction Processing)
OLTP systems are designed for transactional processing of business operations, such as order processing, inventory management, and customer service.
The data is stored in a relational database management system (RDBMS) that is optimized for fast, efficient data processing.
The database schema is normalized to reduce data redundancy and ensure data consistency.
The data is structured in tables, with each table representing a single entity or transaction.
The queries in OLTP systems are simple and usually involve retrieving or updating individual records or small sets of records.
OLTP systems typically have high concurrency and support many users accessing the system simultaneously.
The focus of OLTP is on data accuracy, consistency, and reliability.
OLAP (Online Analytical Processing)
OLAP systems are designed for analytical processing of large datasets, such as data mining, business intelligence, and decision support.
The data is stored in a multidimensional database or data warehouse that is optimized for complex queries and analysis.
The database schema is denormalized to improve query performance and reduce query complexity.
The data is structured in cubes, with each cube representing a summary of data from multiple tables or sources.
The queries in OLAP systems are complex and involve aggregating, grouping, and analyzing large amounts of data.
OLAP systems typically have lower concurrency and support fewer users accessing the system simultaneously.
The focus of OLAP is on data analysis, visualization, and decision-making.
ETL vs ELT
Snowflake supports both ETL and ELT data integration approaches, giving users the flexibility to choose the approach that best fits their needs.
ETL (Extract, Transform, Load)
In the ETL approach, data is extracted from one or more source systems, transformed into a format that can be used by the target system, and then loaded into the target system.
The transformation process is typically done using a separate server or data integration tool, which may involve merging, cleaning, aggregating, or filtering data.
ETL is most commonly used for structured data and for moving data from operational systems to a data warehouse or data mart.
ELT (Extract, Load, Transform)
In the ELT approach, data is extracted from source systems and loaded into the target system as-is, without any transformation.
The transformation process is done within the target system using tools such as SQL, data modelling, or data visualization.
ELT is most commonly used for unstructured or semi-structured data, and for data warehousing architectures that use a distributed processing model.
I've started a detailed series of blogs on Snowflake. Check out my previous blog on the Snowflake series. For more such blogs, do follow me on hashnode and LinkedIn.